
language DNA continued: words
After some major crypto-efforts which did not reveal more than some lines in different languages, i asked myself the question why i did not persue the visual language DNA on more than just letters.
If i could see an image of more letters (2-grams,3-grams) or words in the context of the entire script, this would hugely improve the insight in possible meanings.
At this point i have a preference for Latin and old-‘Alemannische Sprache’.
If i would like to see if for example the words : woman, water and god are present in the text, i only have to create an DNA-image of that word and compare it. Theoreticly this would reveal to me if a word is present, or could be in the text.
This week i completed the coding, which is very simple and the results are nice to see.
More explaining on how the language DNA works on another page but a brief example:
English – Latin
water – aqua
woman – femin… – mulier..
god – deus
If we would now search for ‘femin’ in latin inside the word femininam
this would return return that ‘femin’ sits in front of that word. I call that the A-position.
Statement
The number of repeats of such a piece of text (a string), combined with the position of those pieces and the counts on those pieces on those positions give a good reference towards any other language.
Combining possible references towards a given string from one transliteration (EVA-> Latin for example) will give an anchor point for another string which has the same letters or any partial identical text piece. For example if we found ‘femin’ at a very high percentage only on the A-pos, and we see that there no other words in Latin which start with that, any other word with ‘feminam’ refers to that same word that start with ‘femin’.
Perhaps that is formulated too complicated. Let’s just start:
The highest repeated 2-grams in the entire Currier A+B (CAB) are:
| word | repeated | avg word dist.in words | length |
| ol | 531 | 67,35 | 2 |
| or | 354 | 101,29 | 2 |
| ar | 320 | 111,92 | 2 |
| dy | 250 | 138,29 | 2 |
| al | 229 | 155,28 | 2 |
| am | 77 | 447,83 | 2 |
| sy | 35 | 914,32 | 2 |
| qo | 29 | 1265,43 | 2 |
| os | 26 | 1425,28 | 2 |
| ky | 24 | 1262,91 | 2 |
| om | 22 | 1523,67 | 2 |
| dl | 20 | 1663,42 | 2 |
| do | 16 | 2237,2 | 2 |
| ty | 16 | 1480,07 | 2 |
| lo | 15 | 1838,64 | 2 |
| ly | 14 | 1707,38 | 2 |
| ry | 13 | 2245,33 | 2 |
| lr | 12 | 2811,09 | 2 |
| sh | 12 | 2190,73 | 2 |
| ls | 10 | 2475 | 2 |
| ro | 10 | 3809,22 | 2 |
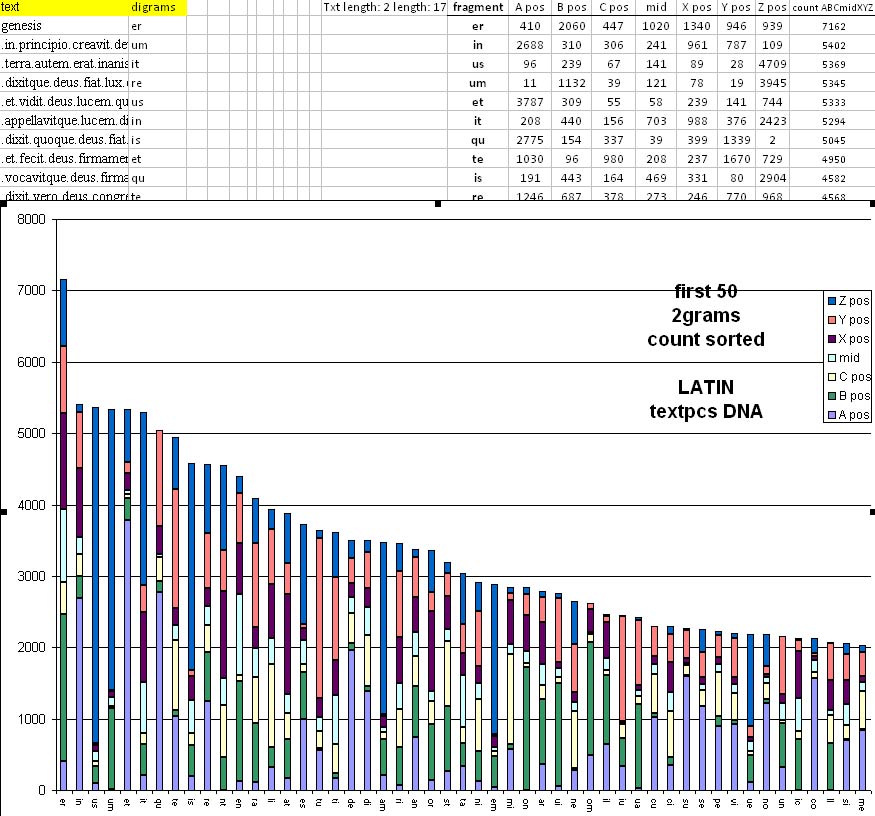
If we then look at the occurences of these 2-grams in the text (full Currier AB NST=no short textpages such as pictures):

The count is the count of occurences in total for a particular 2-gram.
That does not neccessary has to be the same count as the repeat count. For example ‘dy’ is the third highest repeated 2gram, but in occurences as part of word-entities the ‘ai’ has a higher count.
Now we can compare this with Latin. Not only the 2 but also the bigger x-grams dna because it is possible that a 2gram in EVA actually means a 3gram or more in Latin.
Also French displayed:
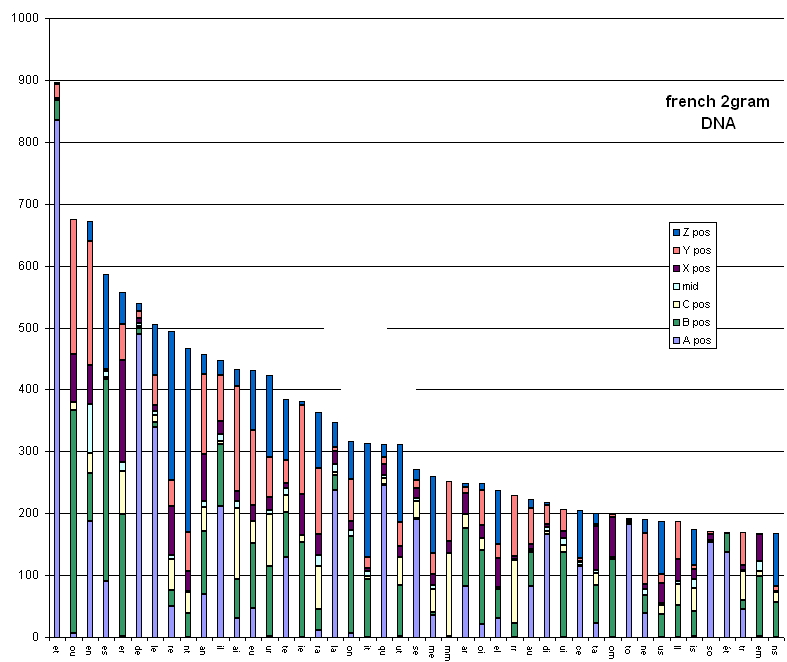
I examined the letters, grams and words but I can not find a good pattern in any of these between the VMS and Latin.
The best pattern you can see is when we look at the CAB big Z-pos on the 2-grams:
The matching 2-grams in Latin must have the same letters either as first or as last, or both.
By substitiution of the letters that match the most i was able to make some sort of sentences like below, but these are very occociasional and too incidental. That is reason i gave up here:
f33v.P.7 tshdy.shefchdy.shckhdy.oltedy.daiin.oky.cheol.orain.chdyshdy.porar.
tdotum.doefaotum.doacotum.intetum.teiis.icum.aoein.ireis.aotumdotum.pirer.
anecdotum ?f39r.P.10 pchdar.shedy.ar.aiir.okair.ykeols.shedy.qockhdy.laiin.syky.
paoter doutum er eiir iceir umcuind doutum qiacotum neiis dumcum
pater dotum erf39v.P.1 pdair.chdy.fdykain.or.air.sheykaiiin.ofchy.kar.or.aiin.dol.ky.oshdy.
pteir.aotum.ftumceis.ir.eir.doeumceiiis.ifaoum.cer.ir.eiis.tin.cum.idotum.
idiotum?org f39v.P.11 sarol.chedy.shekam.qokar.chl.ykeedy.chckhy.dalor.dy.
doucem = advies derin aoutum doucem ricer aon mcuutm aoacom tenir tm
Derin aoutum advies van rijst waren niet mcuutm aoacom hold tmf39v.P.14 tar.aiin.okaiin.cholody
uter ebbs icebbs aqinilum
uter obtice
When we look at the occurence counts of all these things, this is not very surprising.
The number of times letters occur in the VMS compared to Latin is displayed below:
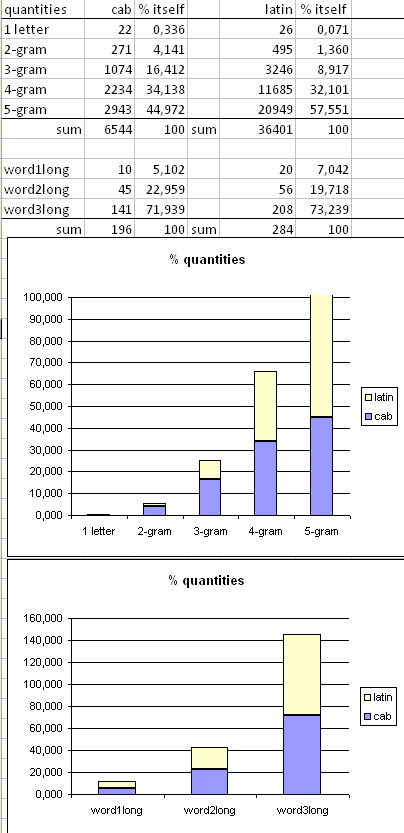
Especially 2 and 3-grams occur twice as many in CAB then they do in Latin. Although the 4-grams are equal but the 5-grams are much lower in CAB. This does not have that effect on 1,2 or 3 letter words.
Again, back to square one. ;-(
I assume that a 2-gram word sometimes is a 3 or 4-gram, and so on.
Furthermore, the EVA letters M, Q and Y behave very awkward and possibly there are either very significant or they are redundant.
aug.2016
Unique words count
Based on the text on this page, taken the
- entire CAB text with Only Paragraphs (labels removed)
- entire CAB text Only Labels (paragraphs removed)
the unique words have been counted in the text.
This time a routine was used that also counts 1-letter words and occurrences of 1 time only. Results
Text pages, unique words: 6920 (of which 4695 have only 1 occurrence)
Label pages, unique words: 2492 (of which 1954 have only 1 occurrence)
Overlapping words in both:
You can find all words as download on this page.
![]()