
unique word repeats vs length
Comparing text unique word repeats versus their word length
2-10-2016
Here the VMS unique word repeats in the entire text are compared with their own length. The resulting values are then compared to known texts, to see whether the found values are an indication and conclusions could be made. This is called “repeats vs wordlength”.
Method
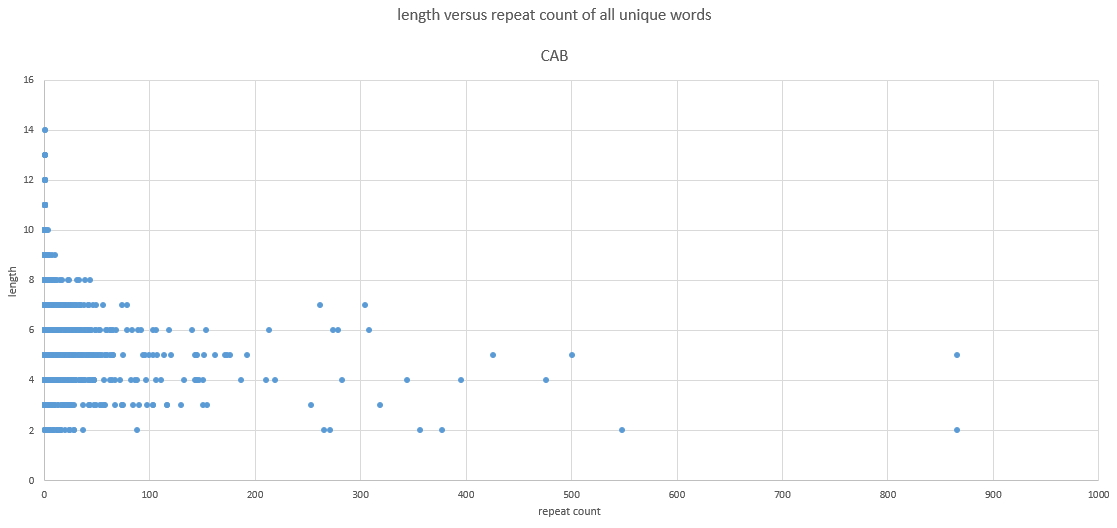
- find the unique words in a text and count the number of times these repeat (word repeats)
- remove words of length 1
- calculate
- sort from high repeat to low and assign word repeat order 1 for the word with the highest repeat, the next one will become number 2 and so on
The resulting graphs are below:
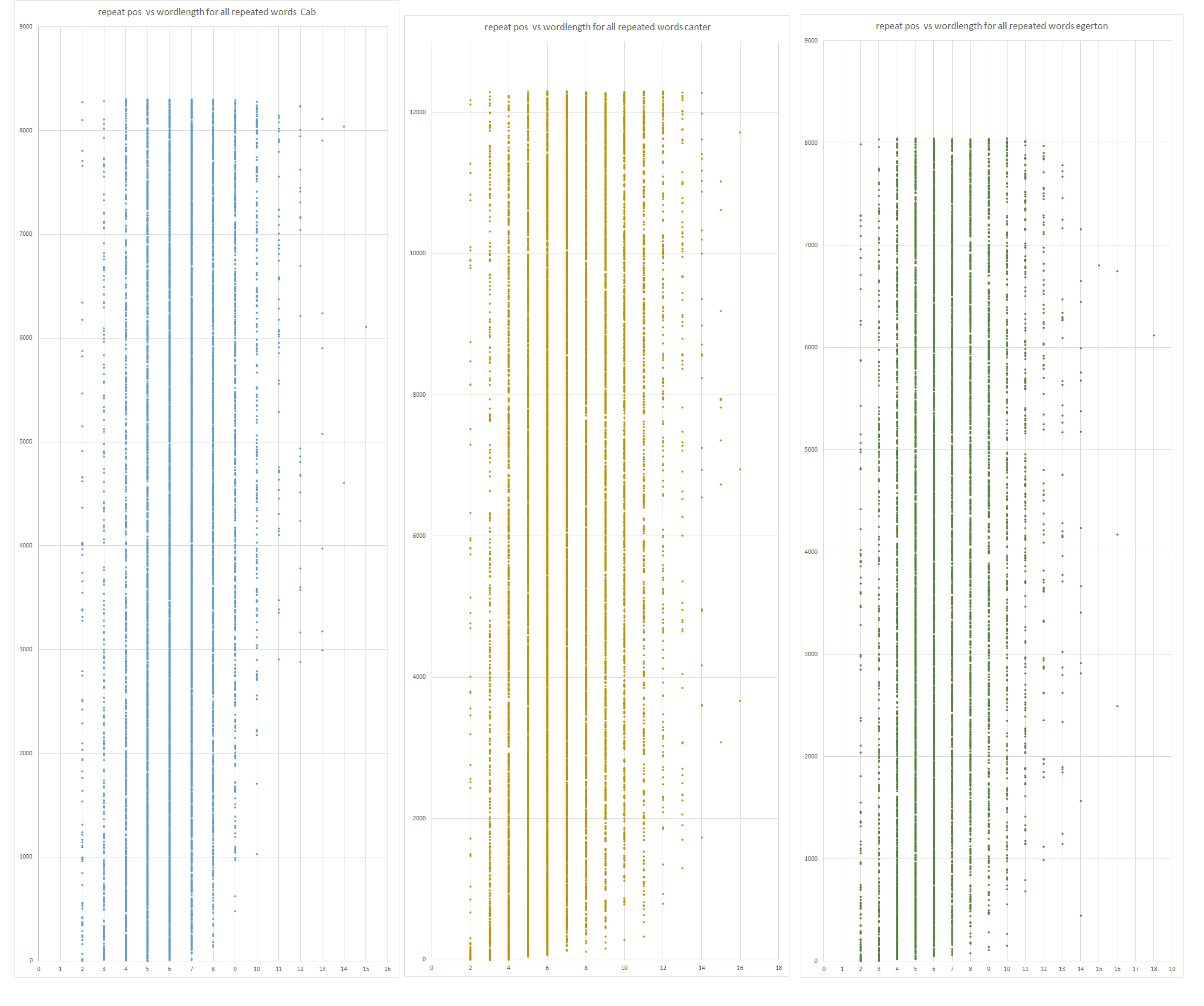
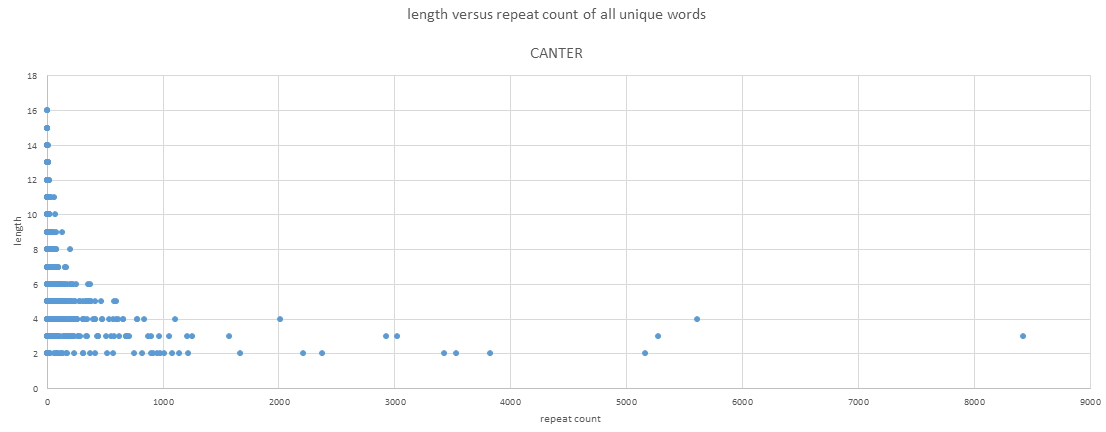
The total CAB with Rosette is taken and the Canter text from around the year 1200 in English. Then the length of those words has been used together with these repeat positions to draw the graph.
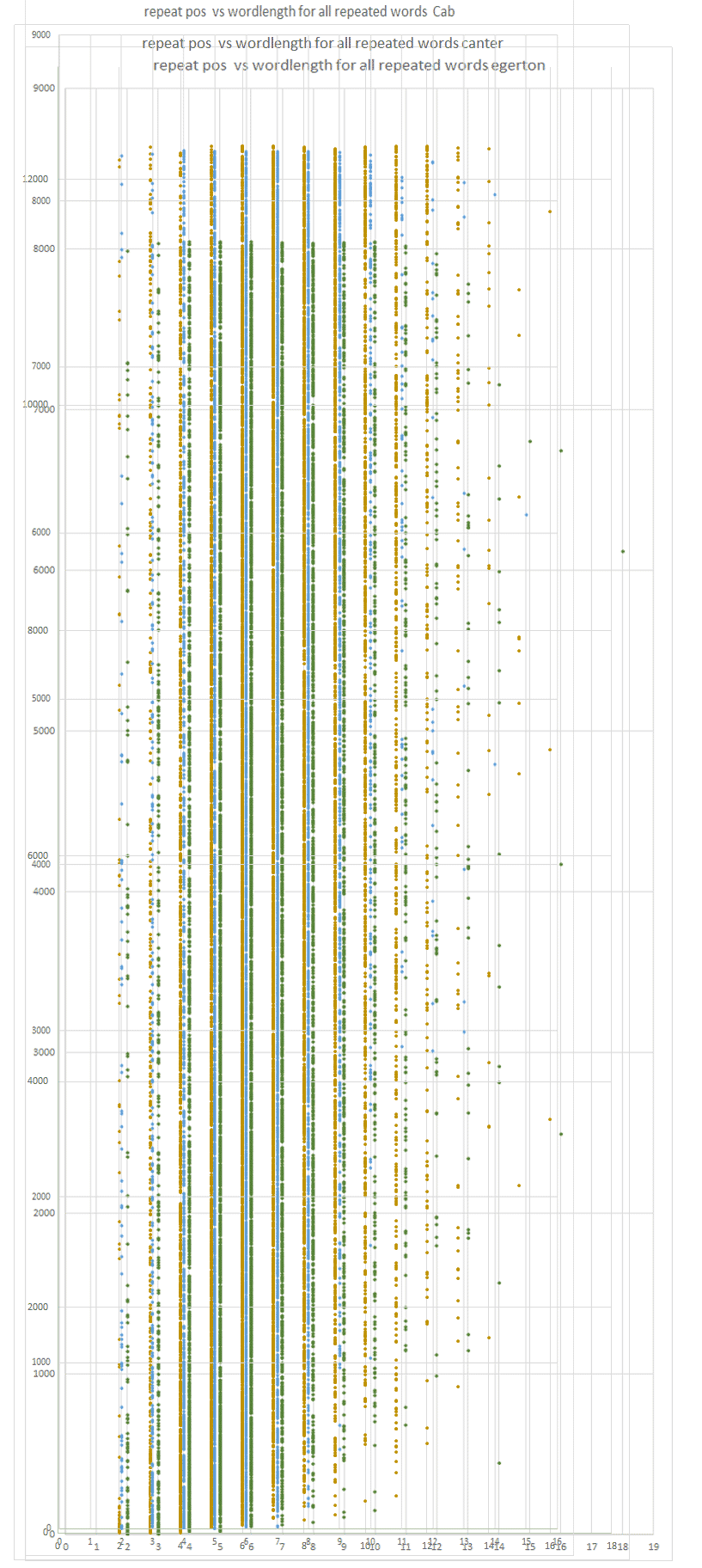
blue=CAB, yellow=Canter, green=Egerton
What you see is that the distribution in CAB is a little bit more compact compared to the Canter words.
At about 10,11,12 the Canter line begins to crumble and on length 12 the dots can not form a line any more, and at 13 it falls apart.
This same behaviour starts on the CAB text at line of length 9 and directly the line falls apart on the next length 10. It shows how compact the wordlength in the VMS language is compared to the English of the year 1200.
Although i used for Canter has 12285 words and for the VMS 8229 unqiue words, the VMS words still lie closer to the same length than in Canter.
If you look at Middle English Egerton with 8046 unique word you can see that the “crumble point” also lies at length 11.
The presented corpora Canter and Egerton are shown to make a point:
many other large corpora (in about 50 different languages from different times year 1100- 2015) could be analyzed but i am confident they will all show the same behaviour, because:
a) the average lengths of the unique words of those corpora are all the same
b) the amount of unique words versus the average length all share the same factor
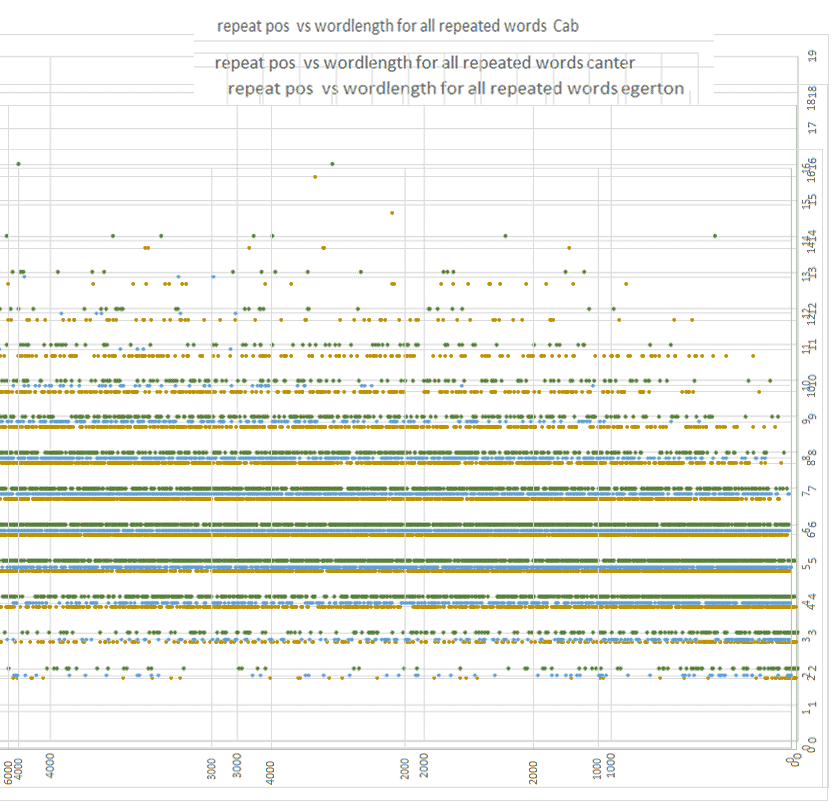
Conclusion comparison “repeats vs wordlength”
What does this mean? It means that
- the number of unique words follow a normal pattern in “repeats vs wordlength”
- the “repeats vs wordlength” in the VMS is a little bit more dense, but they follow a normal pattern in general
![]()